不知道是不是开始学习Hibernate的原因, 最近有点犯困, 总觉得睡不醒.
上一篇的破冰之旅中的最大收获是发现JPA和Hibernate都可以自行创建数据库, 而不用先行创建, 果然爽.
不过例子实在太简单, 这一章是来看看Domain model 和 metadata. 这一篇的内容还是偏理论为主, 还没有真正一个一个介绍具体内容. 不过理论先学好也很有必要, 2019年复习Java的过程中就觉得理论和实践真的是互相加强, 互相融合, 互相推动的.
- Domain Model
- CaveatEmptor系统
- 创建可持久化的类
- 创建可持久化的类 – dirtycheck
- 创建可持久化的类 – 类之间的关系
- metadata 元数据 与 Validator
- 注解方式配置元数据和验证器
- XML方式配置元数据和验证器
- 运行时获取元数据
Domain Model
在一个系统中, Entity用来称呼一个系统中被广为接受的各种概念, 对于一个电商系统来说, 可能会有付款, 订单, 客户, 商品等. 可以看到, 这些概念主要基于商业模型.
基于商业模型, 系统设计师们会设计出一个面向对象的模型, 这个模型依然是概念上的(即不是用某种具体的编程语言写出来的), UML类图就是典型的面向对象的模型的代表.
将这个面向对象的模型中代表Entity的部分, 以及表示Entity之间的关系抽出来, 就组成了 Domain Model, Domain Model实际上是现实世界的抽象.
CaveatEmptor UML类图
例子的数据库就是用于一个CaveatEmptor网站, 这个网站是一个拍卖网站, 采用英式拍卖方式, 即竞拍者可以不断出价, 直到竞拍期结束, 出价最高的人会赢得竞标. 每个商品仅仅会被拍卖一次.
拍卖的商品被分为大类, 然后相似的商品存放在同一个区域和货架上. 拍卖网站会提供分层次的目录以让竞拍者可以浏览商品或者搜索.
选择一个商品之后, 就会跳转到商品详情页, 可以查看商品的图片等信息.
一次拍卖包含一系列的出价, 其中一个是赢得竞标的出价. 竞标人的信息包括姓名, 地址, 付款信息.
通过这些分析, 就可以组织出一个UML图:
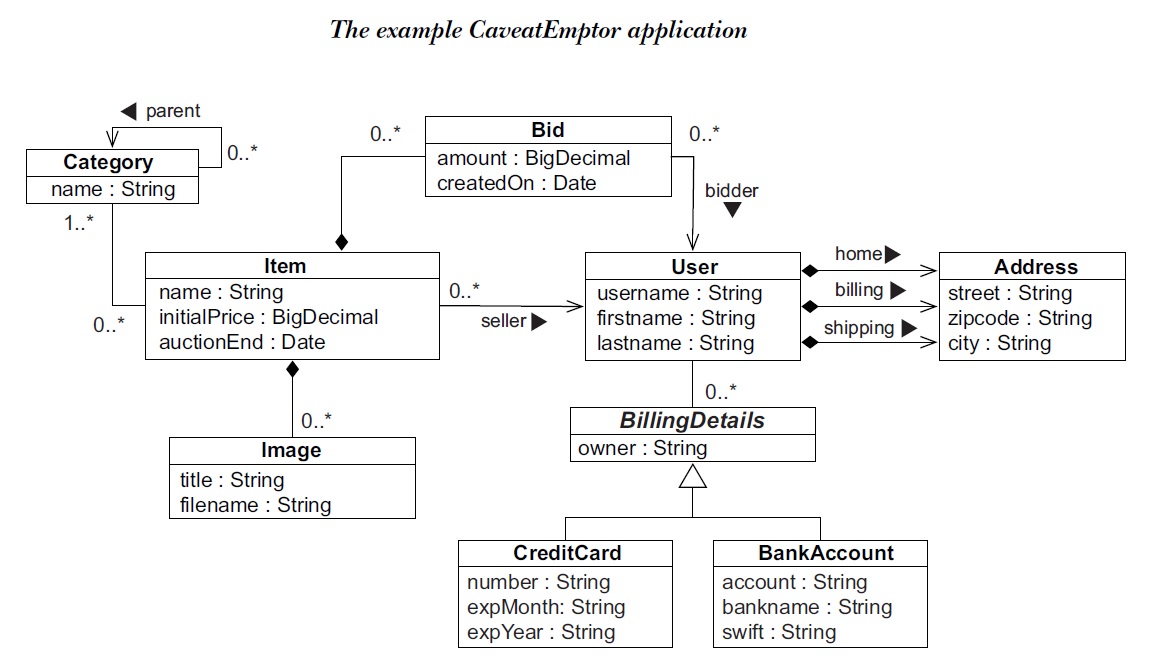
由于一个商品就被拍卖一次, 因此无需单独设置ITEM(表示商品)和AUCTION(表示一次拍卖)两个对象, 仅仅用一个ITEM就可以.
有了ITEM对象后, 很显然, ITEM要属于一个CATEGORY, 一个CATEGORY之下可以没有商品. 此外表示每一次出价的BID显然需要和ITEM关联, 一个ITEM可能有多个出价, 也可能没有出价. 一个BID必然要与一个ITEM关联.
IMAGE也与ITEM有关联, 一个ITEM可能没有也可能有图片, 一个图片对象则一定对应一个ITEM. 所以ITEM 与 BID IMAGE都是组合关系.
CATEGORY比较有意思, 这个UML类图的0..*表示一个CATEGORY最多从属于另外一个CATOGORY, 一个CATEGORY可以有多个子CATEGORY.
USER和BID, USER和ITEM, USER和BillingDetails之间都是0..*的关系, 即一个用户有0到多个BID, ITEM和付款信息, USER和Address是组合关系, 即用户肯定有Address信息.
CreditCard类和BankAccount类继承自BillingDetails类.
这个UML类图是只描述了所有要进行持久化的类, 而且也省略了这些类的方法, 仅关注成员变量, 也就是会被持久化的内容.
创建可持久化的类 – 访问成员变量的方法
接下来的一个关键工作, 就是如何根据UML类图, 创建可以持久化的类.
需要用一个POJO类型的Java Bean类来作为持久化类的基础, 还需要满足如下条件:
- 可以没有get set方法, 可以将Hibernate配置成直接存取字段或者通过方法存取.
- 不能是内部类
- 类本身和所有方法都不能是final, 这是JPA标准的要求.
- JPA和Hibernate都要求必须有一个至少有包可见权限的无参构造器, JavaBean无此要求.
- 与UML类图中规定的成员变量相同
此外, 还有一些特殊的问题需要解决. 一个一个来看. 首先就是Hibernate通过成员变量还是get方法进行操作的问题.
Java的get和set方法(private权限的成员变量+public权限的set/get方法), 实际上提供的是一个隔离, 即可以改变类内部的实现, 而不更改接口. 实际上, 即使没有直接对应set/get方法的成员变量也没有关系.
将Hibernate配置为直接通过反射存取成员变量的时候, 没有问题. 配置成通过get方法访问成员变量的时候, 类内部实际的实现可能与对应的数据库表设计相互分离 – 即没有关系.
看下边这个例子:
public class User {
protected String firstname;
protected String lastname;
public String getName() {
return firstname + ' ' + lastname;
}
public void setName(String name) {
StringTokenizer t = new StringTokenizer(name);
firstname = t.nextToken();
lastname = t.nextToken();
}
}
如果数据库中有name列, 就可以添加这个方法, 但实际的User类并没有该成员变量. 这里经我测试, 在getName上添加注解, 自动生成表的时候不会生成该字段, 还是需要有Name成员变量才行.
这里还一个坑就是如果User类不指定表名, 则User是一个关键字, SQL语句会执行出错.
如果都使用默认的@Id和@GeneratedValue, Hibernate创建的序列对象相同, 如果更新两个类, 都会使用同一个序列对象, 可以具体配置不同的序列对象.
还有就是JPA启动的时候删除表和重新创建表并不在事务管理范围内, 所以会变成每行语句直接提交.
创建可持久化的类 – dirty check
Hibernate如果配置成通过get方法存取, 就要注意Hibernate的检测更新的机制.
Hibernate会自动检测状态改变, 然后将状态改变与更新数据库关联起来. 通常来说, 对于一个成员变量, get方法返回一个与Hibernate赋给这个成员变量的值不同的值, 没有关系, 因为Hibernate对于基本类型是比较值是否相等, 而不是对象内存地址, 比如:
public String getFirstname() {
return new String(firstname);
}
返回一个新的字符串, Hibernate会用.equals来比较, 而不是返回新的字符串和原来作为成员变量的字符串不是同一个对象而因此去更新数据库.
但是对于集合元素, 就不是如此了, Hibernate比较集合元素的时候, 用的是内存地址, 而不是比较其中所有内容是否相同. 所以get方法要返回Hibernate在查询的时候给对象设置上的集合变量, 而不能是一个新的集合, 否则就会触发Hibernate的更新机制. 所以要注意这个特性, 避免造成不必要的更新.
protected String[] names = new String[0];
public void setNames(List<String> names) {
this.names = names.toArray(new String[names.size()]);
}
public List<String> getNames() {
return Arrays.asList(names);
}
如果类写成这样, 虽然getNames返回的是一个其中内容和names参数一样的数组, 但Hibernate会认为是不同的结果, 因此就会去更新names字段, 就会造成不必要的更新. 这一定要注意.
如果直接配置在字段上, 则会破坏类的封装, Hibernate会通过反射直接读取和设置值, 不过一般问题不大.
创建可持久化的类 – 类之间的关系
在上边两个问题中, 主要解决了持久化类的基础设置, 与其他类无关的成员变量设置, 然后还有最重要的是, 类之间的关系如何体现.
以ITEM和BID为例, UML类图中只ITEM中, 标出了name等成员变量, 还标出了ITEM与BID的关系, 即实心菱形的组合关系, 即BID不能离开ITEM单独存在, 必定要成为ITEM(发挥功能)的一部分, ITEM要负责BID的生命周期, 如果ITEM消亡, BID也没有存在必要.
同时0..*表示数量对应关系, 由于没有箭头, 因此关系是双向的, 即BID中应该有一个代表ITEM的变量, ITEM中有一个代表多个BID的变量(一个BID集合).
根据这些分析, 可以简单的写出如下的BID类中表示ITEM的相关部分:
@Entity
public class Bid {
......
protected Item item;
public Item getItem() {
return item;
}
public void setItem(Item item) {
this.item = item;
}
}
而ITEM中的BID, 是一个集合, 这里用SET是因为BID是不能重复的:
public class Item {
protected Set<Bid> bids = new HashSet<Bid>();
public Set<Bid> getBids() {
return bids;
}
public void setBids(Set<Bid> bids) {
this.bids = bids;
}
}
通过这两个类的代码, 标识了这两个类存在bidirectional双向关系, 而且是一对多的关系, 即一个ITEM可拥有多个BID. JPA要求属性的类型必须是java.util.Set/List/Collection三种接口之一. 所以这里是用的多态设置属性.
比较这两个可以看到, BID的item字段没有初始化, 但是由于BID必须对应一个ITEM, 很显然要在创建对象之后立刻为其设置上item属性. Item类的bids属性在一开始就进行了初始化为一个空的set(), 这是JPA的要求, 不能为null.
这里还有一个特殊的类型, 就是要不要使用List, 初看起来似乎List可以保持一个排序, 但实际上数据的完整性并不会因此丢失, 此外还有一些辅助的字段比如TIMESTAMP等可以辅助排序, 如何按照顺序展示, 其实是Java代码的层面, 而不是持久化类的层面.
还一个要注意的是, 对于关系的访问器函数, 也要是public的.
有了上述代码之后, 就可以将两个对象关联起来了:
anItem.getBids().add(aBid); aBid.setItem(anItem)
这两行代码要连续写和执行, 这是因为不如此的话, 就违反了之前的关系, 比如仅仅给Item设置了Bid, 而Bid找不到对应的Item. JPA并不会管关系, 所以这些代码要我们自己维护, 也就是写在Item类或者Bid类或者操作这两个类的代码中.
时刻记得, 现在仅仅是在讨论UML类图到满足UML类图关系的类, 然后在此基础上将其做的符合持久化类的要求, 还没有涉及到如何与数据库打交道.
比较好的写法是带有防御性质的写法, 避免空指针错误, 也避免关联一个已经有了关联的Item的Bid对象:
public void addBid(Bid bid) {
if (bid == null)
throw new NullPointerException("Can't add null Bid");
if (bid.getItem() != null)
throw new IllegalStateException("Bid is already assigned to an Item");
getBids().add(bid);
bid.setItem(this);
}
有了这个方法之后, 一般的套路就是在类中将对应的set方法改成私有, 仅仅通过addBid/addItem这种方法来进行操作, 因为关系只需要确立, 不需要解除. 所以无需再暴露set方法.
关于封装还需要注意的是get方法, 如果直接返回集合, 则可以对集合进行操作, 对于表示关系的这些字段, 则不应该直接返回集合, 否则会被除了addBid/addItem之外的方法修改关系, 所以一般可以返回一个不可变的对象如下:
Collections.unmodifiableCollection(collection) Collections.unmodifiableSet(collection)
还有一个确保关系被设置后不可变的方法就是采取依赖注入, 即将Item作为Bid的构造器, 然后不设置对应的访问器方法, 这样在创建Bid对象的时候, 就关联了Item而且之后无法再变化. 但是这种方法一般不太推荐, 因为Hibernate不会调用这个构造器, 而且创建Bid对象的时候就必须要求Item对象已经创建, 这可能会要求程序必须满足一些流程限制.
最后来总结一下从UML类创建持久化类的要点:
- 有包可见级别的无参构造器
- 访问成员变量可以通过反射也可以通过get方法
- 如果通过get方法, 要注意返回集合的时候, 返回相同内容的新建集合, 会导致Hibernate的更新
- 设置关系的时候采取优化的套路, 也就是检测空指针和是否已经关联之后, 再进行添加, 并且不要对外暴露关系属性相关的访问器方法.
metadata 元数据
元数据是什么, 其实就是注解, 或者是XML配置. 都是提供元数据的一种方式. 在创建好了上边的类之后, 就算在persistence.xml中的class属性或者Hibernate的mapping class=中指定这些类, 也是不起作用的.
这是因为这些类本身还只是POJO, 还没有元数据, 也就是说JPA/Hibernate还不知道如何将这些类的对象持久化. 对于ORM来说, 元数据就是提供给ORM工具(Hibernate)用的.
JPA标准规定了两种提供元数据的方式:
- 注解方式, 也被称为内部方式, 因为注解是包含在Java代码中的
- XML方式, 也被称为外部方式, 因为XML文件并非Java代码
Hibernate在JPA的标准之外还有自己的一些原生功能, 也同样可以通过这两种方法提供元数据. 所以对于现在的我们来说, 要将上边的POJO类加上元数据, 既可以加上注解, 也可以在XML里再多写一点东西.
与JPA的元数据紧密相关的, 还有JSR303 Bean Validation标准, 代表如何去检测一个持久化对象每一个持久化的域是否符合要求. Hibernate也提供了JSR 303的实现, 即Hibernate Validator:
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
<version>6.1.0.Final</version>
</dependency>
JSR303 自然也可以通过注解或者是XML配置
在当今的开发中, 注解方式已经是主流, 对于一些注解方式难以配置的或者特殊的功能, 才会使用XML配置. 不过也要了解一下, 如果要用到老版本就会有XML配置的问题.
注解方式配置元数据和验证
这里其实只是对理论的稍微介绍, 还没有介绍的具体的注解怎么写.
要给持久化类加上注解, 首先要加的就是@Entity注解, 很多时候仅仅有这个注解, 就已经足够ORM工具将其转换成可以写入到数据库中的关系对象.
注解都是类型安全的, 如果赋值错误, 编译的时候就会报错, 所以可以放心大胆使用.
区分JPA标准与Hibernate的注解
- JPA的注解都来自
javax.persistence.* - Hibernate的注解来自
org.hibernate.annotations.*
在给类加注解的时候, 一个好实践是JPA的注解都使用简单的注解类名, 而Hibernate注解都采用完整包名, 比如:
import javax.persistence.Entity;
@Entity
@org.hibernate.annotations.Cache(usage = org.hibernate.annotations.CacheConcurrencyStrategy.READ_WRITE)
public class Item {
}
这么做的好处是如果要更换JPA的提供商, 可以非常清楚的看到哪些属于JPA标准, 哪些注解属于具体提供商, 只需要更换提供商的注解即可.
加上注解之后, 我们的类是否就依赖于JPA呢, 答案是肯定的, 但是仅限于编译时期, JPA的注解都是Runtime的, 必须在运行的时候让ORM工具获得. 不过如果不使用ORM, 则这些类依然可以正常的使用.
全局注解
像@Entity这样的注解, 仅仅在被注解的类中发挥作用. JPA和Hibernate都有一些全局注解, 所谓全局注解, 就是不需要将其注解到某个类上, 就可以发挥作用(比如其他的注解可以知道该注解中的内容), 比如@NamedQuery注解, 无需放在某个持久化类中, 而是可以找一个java文件, 里边只写注解:
@org.hibernate.annotations.GenericGenerator(
name = "ID_GENERATOR",
strategy = "enhanced-sequence",
parameters = {
@org.hibernate.annotations.Parameter(
name = "sequence_name",
value = "JPWH_SEQUENCE"
),
@org.hibernate.annotations.Parameter(
name = "initial_value",
value = "1000"
)
})
package org.jpwh.model;
这个套路我读到这里确实第一次见到, 这么配置之后, 其他的注解里就可以引用这里定义好的注解内容. 确实刺激.
不过我看这个东西还是少用为好, 作者解释了为何这里不用JPA标准的注解, 而使用Hibernate的注解, 因为JPA的注解不具备这样的功能, 作者自己也很奇怪. 所以如果想用JPA的注解, 还是需要将其放在某个功能类上, 而不能在一个.java文件中只写注解.
注解配置验证器
这个和配置元数据没有什么太大不同, 其实可以将其直接认为也是ORM的一个元数据, 因为如今都是二者搭配使用, 形影不离. 注解都来自javax.validation.constraints.*, 例子如下:
import javax.validation.constraints.Future;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
@Entity
public class Item {
@NotNull
@Size(min = 2, max = 255, message = "Name is required, maximum 255 characters.")
protected String name;
@Future
protected Date auctionEnd
...
}
验证注解还可以自定义, 具有很高的灵活性. 加上注解之后, 这些验证字段并不会随时都进行验证, 而是会在指定的时候进行验证. 这分为两种, 一种是手工的代码进行验证, 一种是如果使用Hibernate框架, 加上了验证元数据之后, Hibernate会在classpath下寻找JSR 303的Provider程序, 如果找到, 就会在写入数据库之前进行验证.
手工验证的代码的逻辑就是先创建验证器工厂, 然后获取验证器对象. 之后用一个ConstraintViolation<T>对象来装验证后的结果. 例子如下:
ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
Validator validator = factory.getValidator();
Item item = new Item();
item.setName("Some Item");
item.setAuctionEnd(new Date());
Set<ConstraintViolation<Item>> violations = validator.validate(item);
assertEquals(1, violations.size());
ConstraintViolation<Item> violation = violations.iterator().next();
String failedPropertyName = violation.getPropertyPath().iterator().next().getName();
assertEquals(failedPropertyName, "auctionEnd");
if (Locale.getDefault().getLanguage().equals("en"))
assertEquals(violation.getMessage(), "must be in the future");
手工验证的逻辑还是比较清晰的, 不过一般Hibernate ORM都和Hibernate Validator一起搭配使用, 所以持久化类会在被持久化之前自动进行验证, 如果验证错误, 会抛出ConstraintViolationException, 包含所有的验证错误信息.
在persistence.xml的PU内部, 可以使用<validation-mode>来控制验证, 有三个选项:
AUTO, 如果找到验证器提供商的包, 就进行验证, 找不到就验证.CALLBACK, 强制验证, 如果找不到验证器包, 就报错.NONE, 不进行验证.
XML方式配置元数据
XML配置的元数据的“级别”要比注解“高”一些, XML配置可以完全替代注解, 或者覆盖注解的配置. 所以XML可以完全替代注解.
对于JPA标准来说, persistence.xml中包含持久类的元数据, 而是默认位于/META-INF/orm.xml文件中, 还可以在persistence.xml中通过<mapping-file>来指定其他路径和名称的XML文件.
一个针对最开始的例子Message类的orm.xml的例子如下:
<entity-mappings
version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence/orm
http://xmlns.jcp.org/xml/ns/persistence/orm_2_1.xsd">
<persistence-unit-metadata>
<!-- 表示忽略所有注解和所有其他XML文件中的映射关系, 即仅采用当前文件针对某个类的设置-->
<xml-mapping-metadata-complete/>
<persistence-unit-defaults>
<!-- 自动转义所有SQL关键字-->
<delimited-identifiers/>
</persistence-unit-defaults>
</persistence-unit-metadata>
<entity class="cc.conyli.model.helloworld.Message" access="FIELD">
<attributes>
<id name="id">
<generated-value strategy="AUTO"/>
</id>
<basic name="text"/>
</attributes>
</entity>
</entity-mappings>
然后把Entity的所有注解都删除, persistence.xml中的<class>cc.conyli.model.helloworld.Message</class>可以注释掉. 然后运行JPA的测试, 可以发现正常执行, 说明XML配置生效了.
Hibernate的ORM文件要和持久化类放在同一个路径里, 名称要叫做类名.hbm.xml, Message类的XML文件如下:
<?xml version="1.0"?>
<hibernate-mapping
xmlns="http://www.hibernate.org/xsd/orm/hbm"
package="cc.conyli.model.helloworld"
default-access="field">
<class name="Message">
<id name="id">
<generator class="native"/>
</id>
<property name="text"/>
</class>
<query name="findMessagesHibernate">select i from Message i</query>
<database-object>
<create>create index ITEM_NAME_IDX on Message(text)</create>
<drop>drop index if exists
ITEM_NAME_IDX</drop>
</database-object>
</hibernate-mapping>
其中指定了包名, 和具体的类名, 然后配置了每个属性对应的持久化元数据. 如此配置完之后, 将Message.hbm.xml放在META-INF/下边, 然后需要修改hibernate.cfg.xml中的如下内容:
<hibernate-configuration>
<session-factory>
......
<mapping resource="META-INF/Message.hbm.xml"/>
<!-- <mapping class="cc.conyli.model.helloworld.Message"/>-->
</session-factory>
</hibernate-configuration>
需要注释掉原来的mapping class(Message类上的注解也要删除), 添加红色的语句, 即不直接从类映射, 而是从XML文件映射,
然后运行上一章Hibernate API的测试, 发现也能成功运行.
Hibernate的Mapping是一个完全的映射, 即其他任何的元数据, 包括注解和JPA的XML文件, 都会触发一个”duplicate mapping”错误. 与JPA不同的是, Hibernate的hbm文件必须显式列出每一个要映射的成员变量, 否则便不会持久化该成员变量, 这与JPA标准的@Entity注解有很大区别.
一个@Entity注解就会自动将一个类的所有成员变量都映射成要持久化的属性. 所以Hibernate的XML注解并不是首选, 也可以这么说, Hibernate是在JPA之下对映射要求配置更多细节. 所以一般除了Hibernate特有的东西, 无需使用Hibernate的XML元数据配置. 后边还会遇到Hibernate特有的功能, 那个时候就需要用到XML了.
至于验证器, 一般不采用XML配置.
运行时获取元数据
在开发阶段知道所有元数据固然好, 如果需要运行时操作元数据, JPA提供了一个API, 通过EntityManagerFactory来获取Metamodel对象, 以此来操作元数据. 看一个例子:
public void testMetaModel() {
EntityManagerFactory emf = CaveatEmptorUtil.getEntityManagerFactory();
Metamodel mm = emf.getMetamodel();
Set<ManagedType<?>> managedTypes = mm.getManagedTypes();
System.out.println(managedTypes);
//判断有元数据的类有几个, 目前其实就一个, 也就是Message类
assertEquals(managedTypes.size(), 1);
//获取其中的第一个也是唯一一个ManagedType
ManagedType type = managedTypes.iterator().next();
//查看这个ManagedType的持久化类型, 是javax.persistence.metamodel.Type.PersistenceType.ENTITY类型
System.out.println(type.getPersistenceType());
//查看ManagedType的Java类型, 发现就是cc.conyli.model.helloworld.Message
System.out.println(type.getJavaType());
//获取这个类中名称为text的属性, 查看这个属性的Java类型, 结果是String类型
SingularAttribute text = type.getDeclaredSingularAttribute("text");
System.out.println(text.getJavaType());
//查看这个text属性对应的持久化类型,是javax.persistence.metamodel.Attribute.PersistentAttributeType.BASIC类型
System.out.println(text.getPersistentAttributeType());
}
通过这个例子可以知道, ORM框架在内部, 将每个类T转换成一个ManagedType<T>类型, 其中包含了原来的类的所有数据和用于持久化的元数据, 包括Java类型与持久化类型, 每个成员变量的Java类型以及对应的持久化类型.
ORM通过这个方式, 一方面可以让ManagedType<T>与普通Java类交互, 另一方面可以将其持久化.
再深入其实就是具体API了, 不多深究了.
总体来看, 这一部分加上前边的最简单的小例子, 其实是勾画出了ORM框架的大致结构, 包括JPA与Hibernate实现, 配置与持久化类的编写, 以及如何操作进行持久化的API, 外加上验证. ORM的本质就是这些东西.
看来老外写的书还真不错, 继续看下去了, 后边就逐渐开始是具体技术了.
其实通过这个UML图也能大概想到, 一对多, 多对多, 还有那个CATEGORY自身的递归查询, 估计在后边都会涉及到. 既然要学, 就继续加油吧.